
Querying Data
Faros provides a flexible GraphQL API to query data across all connected sources. GraphQL is one of the standard query languages. To learn more about it please visit the GraphQL website.
Trying out GraphQL
Each type of data is represented by a model and relationships to other models. For example, consider this GraphQL query for VCS Pull Requests:
query {
vcs_PullRequest {
author {
email
}
commits {
commit {
sha
}
}
}
}This query returns all your pull requests, as well as information about the PR authors and related commits. This is the power of Faros’ GraphQL API: you can accomplish with a single query, what would ordinarily require multiple API calls (with potentially multiple credentials) to multiple remote APIs.
To browse available models and the relationships among them, use a GraphiQL browser like the one embedded in the Faros app under Dashboards > Query Ingested Data
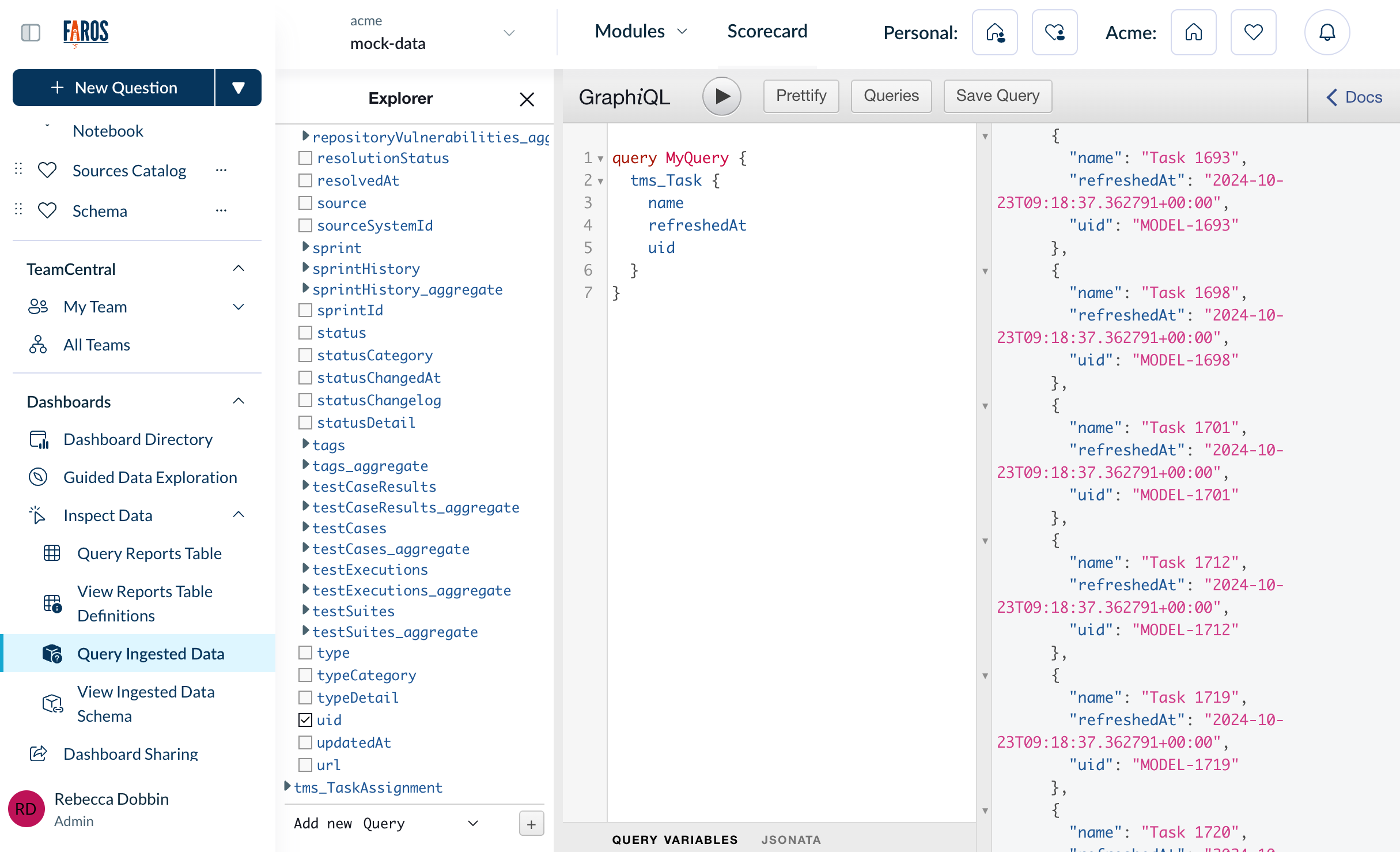
Querying data across sources
In addition to querying data from within a source, the Faros GraphQL API also enables querying data from across sources. For instance, if you've connected up both your CI/CD systems and source control systems to Faros, you can query all the builds associated with your 10 most recent commits with the following query:
query CommitsAndBuilds {
vcs_Commit {
sha
message
repository {
name
createdAt
}
buildAssociations {
build {
startedAt
endedAt
statusCategory
statusDetail
}
}
}
}Here the commits may come from a source control system such as GitHub and the builds from a CI/CD system such as Jenkins. But you can retrieve information from across both these systems with a single query: Faros automatically resolves the joins.
Filtering your data
Faros uses Hasura as its GraphQL backend. As such, you can use all the power of Hasura query filtering to explore your data. As example, consider how we filter by adding a where directive to previous example:
query FilteredCommitsAndBuilds {
vcs_Commit(where: {message:{_like: "%GHA%"}}) {
sha
message
repository {
name
createdAt
}
buildAssociations {
build {
startedAt
endedAt
statusCategory
statusDetail
}
}
}
}Pagination
By default, all query results are limited to a maximum of 1000 records. If you need access to more than 1000 records, you'll have to paginate your queries.
Pagination is a common technique used in systems that work with a lot of data. In essence, it's a way to retrieve data in chunks or "pages" rather than all at once.
There are several different ways to construct a paginated query. The technique that Faros recommends for our GraphQL database is called Keyset Pagination, where we paginate records based on the primary id.
For an example consider this simple, unpaginated query on TMS Task:
query {
tms_Task {
uid
}
}In order to paginate, we add limit, order_by and where directives to the query. We also add the id field to the selection set.
query {
tms_Task(
limit: 10
order_by: { id: asc }
where: { id: { _gt: "" } }
) {
id
uid
}
}For our first page, we specify an empty string ("") for the id in the where directive. We specify limit: 10 to indicate we want pages of up to 10 values. Note: limit value can be as large as 1000.
Then, assuming the last value of our 1st page is
{
"id": "0026f6a327591a1c814d6ddad827af8e6f95a19b",
"uid": "ABC-5786"
}We would retrieve the 2nd page with the following query:
query {
tms_Task(
limit: 10
order_by: { id: asc }
where: { id: { _gt: "0026f6a327591a1c814d6ddad827af8e6f95a19b" } }
) {
id
uid
}
}We would continue like this until we receive a page with less than 10 (the value of our limit directive) results.
Example Implementation
Assuming we have the following paginated query:
query paginated($after: String, $limit: Int) {
cicd_Build(
limit: $limit,
where: { id: {_gt: $after} }
order_by: {id: asc}
) {
_id:id
uid name
}
}And an API for executing a query and returning the result in a Pandas DataFrame:
def query(self, query_str, variables) -> pd.DataFrameWe can implement pagination as follows:
def query_pages(self, query_str, page_size=100, max_pages=None, cursor_field='_id') -> pd.DataFrame:
cursor = ''
pages = 0
result = pd.DataFrame()
while True:
page = self.query(query_str, {'limit': page_size, 'after': cursor})
pages = pages + 1
result = pd.concat([result, page], ignore_index=True)
if len(page) < page_size or (max_pages is not None and pages >= max_pages):
break
cursor = page.iloc[-1][cursor_field]
return resultThe query_pages method builds a single Pandas DataFrame by paginating through a query result. It iterates through the paginated query results, updating the cursor to fetch subsequent pages until the break condition is met, and then returns the final concatenated DataFrame.
Updated 5 months ago